
Build vs Buy: Navigating the Complexity of OTP Verification
A practical guide to OTP verification systems. Compare build vs buy approaches, explore infrastructure complexity, costs, fraud risks, and what teams need to scale authentication reliably.

Rowan Haddad
Content & SEO Manager
Summary
Building OTP verification looks simple — just send a 6-digit code — but quickly becomes a distributed systems problem involving delivery optimization, retry logic, fraud prevention, and global carrier relationships. While AI tools lower the barrier to writing code, they don't eliminate production complexity, making buy-vs-build a more nuanced decision than most teams expect.
Building or buying software is a decision every product and engineering team faces, regardless of company size or stage. When it comes to authentication, and specifically OTP verification, this choice becomes even more critical.
With AI tools accelerating development, the barrier to building software has never been lower with teams assembling systems faster than ever before. However, while AI makes it easier to write code, it doesn’t eliminate the complexity of running systems in production, especially for those that require high reliability, security and global performance.
At first glance, building an OTP system seems straightforward enough. Whatever choice you make when it comes to your authentication process will not only have major security implications but also will affect user experience, engineering bandwidth, and the long-term cost of maintaining the system.
You may consider building your own OTP flows but teams often underestimate the complexities that come with it. After all, how complex can sending a 6-digit code be? In practice, what appears simple quickly becomes a distributed systems problem, one that involves message delivery optimization, retry logic, fraud prevention and global infrastructure considerations.
The stakes are also unusually high as authentication systems handle high volumes of personal and sensitive user data, making them a prime target for abuse and attacks which could lead to security breaches, degraded user trust and lasting reputational damage. According to a report by CrowdStrike, AI-driven attacks have surged by 89% over the past year alone, with breakout times now averaging just 29 minutes, allowing attackers to move from initial access to impact faster than ever.
That level of risk is also why the build vs buy decision matters more than ever.
As a general rule, if it’s not part of your core product, it’s worth reconsidering whether to build it yourself. Because for most teams, the real challenge isn’t implementing OTP, it’s actually operating it reliably at scale.
What an OTP Verification System Actually Includes
At first glance, SMS OTP flows seem straightforward: a user requests access to a system, receives an OTP code to their device, enters it and they’re in. The concept in itself is simple but its implementation is more complex that teams actually anticipate.
In reality, that simple interaction sits on top of a system that has to generate, securely deliver and validate those codes, often across various regions and networks.
OTP verification is more than just sending a message. What happens behind the scenes, including how the code is created, delivered and validated, is far more complicated. The real challenge is doing this safely and at scale.
Core components of an OTP verification system
OTP Generation
An OTP system begins with code generation but even that is more nuanced than it appears.
The ultimate goal of any SMS OTP system is to ensure that only the right user gets the code and that this code is:
Works just one time
Expires within a quick time frame
Is delivered correctly and quickly, even during traffic spikes
Resists attacks
The system must then manage its entire lifecycle, from its generation, validity period to its expiration.
Without careful lifecycle management, systems can become vulnerable to replay attacks or lead to a poor user experience.
Secure Storage
Once generated, the code must be securely stored to prevent exposure, often through hashing or encryption.
This is especially critical as authentication systems are a prime target for attackers so it’s essential to enforce strict validation rules during verification as any small weakness in how codes are validated or stored can be exploited.
SMS Routing and Delivery Optimization
Delivery introduces another layer of complexity. Performance varies significantly depending on region, carriers and routing decisions.
Ensuring that a message reaches a user quickly and reliably often requires dynamic routing logic, awareness of regional constraints, and the ability to adapt to inconsistent carrier behavior.
What works well in one country or region may fail silently in another.
Retry and Fallback Logic
Even with routing optimized, successful delivery is never a guarantee. Messages can be delayed or fail to reach their destination altogether, which makes retry and fallback logic critical.
A well-designed system must be able to determine when to resend a code without overwhelming the user and how to handle the in-between, that is a delayed OTP that arrives after a newer code has already been sent. The system should efficiently handle delays and resends including having a limit on the number of resends and always invalidate old OTPs if a new one is re-sent to keep the authentication process secure.
Furthermore, a robust OTP system should not rely on a single delivery path. It needs to have automated fallback mechanisms that can switch to another provider or an alternate channel. This means that if a primary route is degraded or unavailable, the system should seamlessly reroute messages through an alternative provider or fail over to another channel altogether.
Otherwise, delivery failures become single points of failure which directly impact login success rates and user trust, thereby negatively impacting conversion rates.
Rate Limiting and Abuse Prevention
At the same time, SMS OTP systems must continuously defend against a wide range of attacks. One common threat is SMS pumping, where attackers generate large volumes of OTP requests to premium-rate numbers or specific regions, driving up messaging costs. In parallel, there are brute-force attempts where attackers repeatedly try different code combinations to gain unauthorized access. There are just a couple of the many ways OTP endpoints can be exploited. .
Because these attacks often mimic legitimate traffic, they can go undetected until costs have already escalated, turning such systems into a cost liability.
Addressing such risks require advanced approaches, such as pattern recognition, anomaly detection and behavioral analysis to distinguish between legitimate and malicious activity.
As attack methods evolve, these safeguards need continuous tuning, making fraud and abuse an ongoing effort that requires constant adaptation.
Monitoring and analytics
It’s important to have high-level visibility to make sure that messages are being delivered and determine whether there are delays and where failures occur.
A robust OTP system should allow you to monitor key metrics such as delivery rates, latency and failure patterns. Centralized dashboards, combined with real-time alerting, allow teams to detect and respond to issues before they impact users at scale. Without this level of visibility, failures go unnoticed until they affect user trust or conversion.
Having continuous and real-time observability is the best way to optimize the performance of an OTP system.
Quick check: What a reliable OTP system actually requires
✔ Can we securely generate, store, and expire OTPs correctly?
✔ Do we handle OTP lifecycle (validation, invalidation, edge cases)?
✔ Are messages routed and optimized for global delivery?
✔ Do we have retry and fallback logic if delivery fails?
✔ Have we implemented rate limiting and abuse prevention?
✔ Do we have visibility into delivery, latency, and failures?
When it Makes Sense to Build an SMS OTP System In-House
After looking in-depth at what an OTP system actually looks like, a lot of teams may decide it’s not worth the hassle. However, there are specific scenarios where building your own OTP system can be a justified choice.
Quick check: Should you build OTP in-house?
Do we have a mature infrastructure and security team?
Do we require full control over data and compliance?
Are we operating at a scale where optimization matters?
Is OTP central to our product experience or conversion?
Are we prepared to maintain and evolve this system long-term?
If you answered yes to most of these questions then you’re on the right track to building your own system. Let’s take a deeper look at what it all entails.
You have a mature infrastructure and security team
As we’ve seen, OTP systems are not standalone features. OTP verification may appear lightweight on the surface but in practice it relies on infrastructure that must be highly available, globally distributed, and resilient to failure.
Building and operating this kind of mature infrastructure requires teams with experience in distributed systems, reliability engineering, security and large-scale backend systems along with dedicated teams who can monitor system health, respond to incidents and continuously optimize performance. Even small disruptions in delivery or latency can directly impact user experience, making reliability a core requirement rather than an afterthought.
Additionally, OTP systems are a frequent target for fraud and abuse. If you choose to build then that means taking full responsibility for securing the entire flow. This requires not only implementing safeguards, but also continuously evolving them as attack patterns change.
Finally, the work that goes into OTP systems doesn’t end once the system is built. It requires ongoing maintenance, monitoring and iteration. Organizations that already operate similar systems such as messaging platforms or authentication services are better positioned to handle such complexity.
You need full control over data and compliance
Building in-house makes sense when you need full control over data and compliance. This is particularly relevant for organizations within the financial, healthcare or government industries that often operate under strict regulatory requirements around how data is stored and used.
In these cases, relying on third-party providers may introduce risks or constraints, particularly if those providers can’t guarantee how and where data is processed.
On the one hand, maintaining full ownership of the authentication flow makes it easier for these organizations to meet internal security standards, pass compliance audits, and align with regulatory frameworks.
On the other hand, this level of control comes with added responsibility. Teams must ensure that their implementation meets all relevant security and regulatory standards, and that systems are continuously updated as requirements evolve. This requires ongoing investment in both infrastructure and processes.
You operate at a very large scale
Scale is another important factor to consider when choosing whether to build your own system. When operating at a high scale, sending large volumes of OTP requests per day, organizations may choose to build in order to gain better control over how messages are routed, dynamically selecting providers based on cost, performance, or regional reliability.
In this case, organizations may benefit from directly negotiating with carriers, optimizing routing strategies, and fine-tuning performance in ways that are difficult to achieve through standard APIs.
However, these optimizations introduce a new layer of complexity. Dynamic routing requires custom logic and constant tuning. Managing multiple providers brings procurement overhead, contract negotiations, and ongoing vendor management. What begins as an effort to reduce costs can quickly evolve into an operational burden, with teams responsible for maintaining routing systems, monitoring performance, and resolving delivery issues across regions.
In addition, large-scale systems require more sophisticated infrastructure that demand robust queuing systems, efficient retry mechanism and the ability to handle sudden spikes in traffic without performance being degraded. Not to mention that products operating at a global scale must account for regional differences in carriers, regulations and network reliability which adds another level of complexity.
Operating at this level introduces new challenges as the more you scale, the more moving parts you bring including multiple providers, routing logic, performance monitoring, and cost management. Eventually, you end up with a complex system that requires its own dedicated engineering and resources to maintain long-term, which means it’s essential to consider whether the benefits of optimization outweigh the long-term costs of owning and maintaining the system.
For smaller companies, the challenge is slightly different. It’s not just scale but anticipating it. These companies often need to build systems that can grow with them but without having access to the same resources or expertise as larger organizations to build for scale. As a result, teams are forced to make tradeoffs, either investing early in more complex infrastructure than they currently need, or starting simple and risking limitations as they scale.
OTP is a core part of your product experience
For some, OTP is actually the core part of the product rather than a supporting function. For applications such as marketplaces or fintech platforms, where authentication is frequent and tied to key user actions, OTP plays a more central role, directly impacting user experience, thereby influencing conversion rates.
In such cases, teams often require a higher degree of control from optimizing delivery speed in specific regions, or tailoring verification flows based on user behavior and risk signals to smaller improvements such as increasing delivery success rates, all of which have a direct impact on user engagement and revenue.
As a result, building in-house makes sense when teams need the flexibility to deeply optimize and integrate verification into their core user flows.
Ultimately, building in-house makes sense if you’re willing to treat OTP as infrastructure rather than a one-time feature. This means fully committing to ongoing maintenance, monitoring, and iteration. Teams need to be all hands on deck and be ready to respond to any incidents, optimize performance and invest in long-term reliability.
For organizations looking for full control and flexibility, building is usually the go-to option. For everyone else, the challenge isn’t just implementing OTP but also sustaining and scaling the system over time.
What starts as a single OTP system often grows into a collection of interconnected components: multiple SMS providers for coverage and redundancy, custom routing logic to optimize delivery, separate tools for fraud prevention, and internal dashboards to track performance. Over time, teams find themselves managing not just a system, but a fragmented stack with many moving parts.
Understanding the nature of a fragmented system and the operational overhead that comes with it is key to evaluating the real cost of building your own OTP infrastructure.
The Reality of Building Your Own OTP System
Even when the decision to build in-house is justified, the operational reality is more complex than it seems. What looks like a straightforward authentication feature quickly expands into a fragmented system that must perform reliably over time and under pressure.
The fact is teams often greatly underestimate just how complex an OTP system is beneath the surface, making the build and implementation and process a bigger challenge than anticipated.
Let’s take a look at what it really takes to build your own OTP system with a few questions for you and your team to consider:
Are we prepared to manage distributed systems complexity?
Can we handle global SMS delivery across regions and carriers?
Do we have systems in place to detect and prevent fraud?
Can we reliably detect and debug silent delivery failures?
Do we have resources for ongoing maintenance and incident response?
Infrastructure complexity
An OTP system is a fragmented, distributed system problem. Every verification request has to be processed in real time under strict latency constraints while interacting with multiple external dependencies such as SMS gateways, databases, and fallback services.
This means the system must be designed to handle retries, timeouts and partial failures without duplicating messages or breaking the user flow. OTP systems must also be able to function reliably under unpredictable conditions, such as sudden traffic spikes without degradation.
Failure handling is one of the most critical aspects of this architecture. External SMS providers may experience latency, throttling, or downtime, and internal services may also fail under load. The system must be designed to effectively handle these scenarios through retries, timeouts, and fallback logic.
A further challenge is ensuring consistency across asynchronous processes. An OTP may be generated, queued, partially delivered, retried, or delayed, sometimes even arriving out of order relative to newer codes. The system must ensure that only the most recent valid code is accepted, while older codes are invalidated correctly across all states.
Observability also becomes essential at this layer. Debugging issues often requires tracing a single OTP request across multiple services and external providers, which can be difficult without unified logging and monitoring.
As a result, such systems require careful architectural planning, deep understanding of failure modes, and ongoing operational oversight to ensure consistent performance at scale.
Global SMS Delivery
Delivering SMS globally is far from uniform. It depends on a fragmented ecosystem of carriers, aggregators, and regional regulations, each with its own constraints and performance characteristics. Each country has its own carrier requirements, regulatory constraints, and delivery behaviors that directly impact delivery success rates.
For example, carrier behavior varies significantly across regions. Delivery speed, reliability and throughput can differ depending on the local network, routing paths and even time of day. This means that achieving consistent delivery often requires dynamically selecting providers or routes based on regional performance.
Consequently, teams need to maintain complex routing logic that determines how messages are delivered based on a combination of factors including geography, cost and performance. In many cases, this involves establishing strong carrier relationships and understanding regional nuances.
Plus, these conditions are not static. Carrier performance fluctuates, regulations evolve, and routing effectiveness can change over time. Ensuring reliable OTP delivery across regions requires continuous optimization, monitoring, and adaptation to local constraints.
Fraud & Abuse
OTP systems are a frequent target of attacks, many of which mimic real traffic and legitimate usage patterns. Common examples include SMS pumping, where attackers generate large volumes of messages to drive up costs, bot-driven attacks that flood verification endpoints and number recycling attacks where previously used phone numbers are exploited to gain unauthorized access.
Detecting such attacks is not so straightforward, making fraud an ongoing challenge that requires layered defenses, continuous monitoring and adaptation as attack techniques evolve.
Reliability: The Silent Failure Problem
OTP systems are expected to be highly reliable and yet achieving consistent delivery at scale is difficult in practice.
As discussed, delivery success rates vary depending on the region, carrier behavior and network conditions. There’s also the issue of messages being successfully sent but that still arrive late, out of order or not at all, creating major inconsistencies in user experience.
This means that OTP systems shouldn’t have a single point of failure. To mitigate this, systems often require redundancy, or using multiple providers or delivery paths to ensure messages are successfully delivered if one fails or underperforms. However, this will require teams to build logic to not only detect these failures but also switch providers in real-time and ensure fallback mechanisms work seamlessly without the risk of message duplication or affecting the user experience.
Such failures are more often than not silent where messages are delayed or dropped without clear error signals. Without unified visibility across providers and regions, teams often struggle to diagnose issues quickly, leading to degraded user experience and reduced conversion rates without clear root causes.
The most damaging OTP failures aren’t the ones that break but the ones you don’t notice.
Maintenance Never Stops
With providers changing their APIs, carrier behavior shifting across regions, fraud patterns evolving and infrastructure requirements growing over time, OTP systems need to be continuously monitored and updated to keep up with these changes and maintain their performance and reliability.
In addition, with issues constantly coming up, incident handling becomes a recurring responsibility. This means teams need to be well-prepared to respond to delivery outages, investigate anomalies and implement fixes under strict time constraints.
Over time, a simple authentication feature quickly turns into a system that requires dedicated ownership and long-term engineering resources.
The True Cost of Building OTP Infrastructure
While the build approach can bring many benefits including full control and ownership of the solution as well as potentially save costs usually associated with third-party solutions, the trade-offs can be significant.
Teams must now spend significant time and effort on not just building the solution but also maintaining it long-term, which may divert their attention from their core operations.
Moreover, the gap between implementing OTP and operating it reliably at scale is significant and the complex nature of these systems doesn’t only impact engineering but also directly drives long-term costs.
One of the most common misconceptions about building OTP systems in-house is that the primary cost is technical, focused on SMS pricing and infrastructure. While those cost considerations are valid and significant, the total costs extend beyond what is actually visible.
While direct costs are relatively easy to estimate, the hidden and ongoing operational costs are often what make building significantly more expensive over time.
Direct Costs
At a baseline level, OTP systems incur direct, measurable costs.
The most obvious one is SMS spend. Each OTP sent carries a per-message cost, which varies depending on destination, carrier and routing path. As OTPs increase in volume, costs can quickly become substantial, especially in regions with high messaging fees.
There are also costs associated with running the system itself. This includes compute resources, databases for storing OTPs and session data, queuing systems for handling traffic, and monitoring tools to track system performance.
However, these costs only represent a portion of the investment required to operate these systems.
Hidden Costs
Engineering time
An OTP system requires continuous maintenance, optimization and troubleshooting beyond initial implementation. This includes defining routing logic, improving delivery rates, updating integrations with providers, and responding to performance issues.
Due to its complexity, an OTP infrastructure becomes a recurring engineering commitment rather than a one-time effort.
Opportunity cost
Any time spent on building and maintaining OTP systems is time not spent on core product development.
As mentioned earlier, teams must now spend substantial time maintaining the system and responding to incidents at any moment’s notice. For teams where authentication is not a core, differentiating feature, building in-house takes away from engineering resources from higher-impact initiatives such as product innovation, growth features or user experience improvements.
This tradeoff is often underestimated yet its impact is significant, particularly in fast-moving organizations where speed to market is critical.
Incident recovery
OTP systems directly affect user access, which means any failures can have immediate (and negative) impact. When issues occur, such as delivery or provider outages, teams must quickly address these issues to minimize disruption.
Incident response usually requires cross-functional efforts, including debugging across multiple systems and external providers.
Therefore, these situations are time-sensitive, unpredictable and require ample resources, which further adds to the operational burden over time.
Procurement and vendor management
Beyond technical implementation, teams must also take into account the responsibility of managing external providers.
This includes sourcing SMS vendors, negotiating contracts, monitoring pricing changes, and maintaining relationships across regions. For teams using multiple providers to ensure coverage and redundancy, this overhead increases significantly.
These procurement and vendor management efforts are rarely accounted for upfront, yet they introduce ongoing complexity and cost that scale with the system.
The real cost of an OTP system extends beyond just sending that message. It's all the costs of operating, maintaining and updating the system over time.
Build vs Buy: Cost Breakdown Comparison
Cost Category | Build In-House | Buy (OTP Provider) |
SMS / Usage Costs | Direct carrier or aggregator pricing (can optimize at scale, but requires effort) | Pay-per-use pricing, typically bundled with delivery optimization |
Infrastructure | Hosting, databases, queues, monitoring systems | Included in provider pricing |
Initial Engineering | High upfront cost to design, build, and integrate system | Low - API integration typically takes days to weeks |
Ongoing Engineering | Continuous maintenance, optimization, and updates | Minimal—handled by provider |
Opportunity Cost | High - engineering time diverted from core product | Low - teams focus on product development |
Fraud & Abuse Prevention | Requires building and maintaining detection systems | Often built-in or partially handled |
Reliability Engineering | Internal responsibility (failover, retries, monitoring) | Managed by provider (SLAs, redundancy) |
Multi-Provider Management | Required for redundancy and optimization | Not required (or abstracted away) |
Procurement & Negotiation | High - vendor sourcing, contracts, pricing negotiations | None - single vendor relationship |
Vendor Management | Ongoing coordination across multiple providers | Minimal |
Global Compliance | Internal responsibility (regulations, sender IDs, registration) | Typically handled or guided by provider |
Observability & Analytics | Must build dashboards, alerts, and reporting | Often included out-of-the-box |
Incident Response | Fully owned internally | Shared or handled by provider |
Time to Market | Slow - weeks to months | Fast - days to weeks |
Scalability Costs | Requires ongoing infra and architecture investment | Scales with usage |
How Verifications APIs work (And Where They Help)
Given the complex nature of OTP systems, many businesses opt for verification APIs to simplify implementation and offload operational burden.
Verify APIs enable businesses to verify phone numbers and/or email addresses. They take on managing the full verification lifecycle, from initiating the verification, sending OTP messages and performing retries, to checking the validity of the OTP code and returning the result.
In that sense, instead of building and maintaining the full system, teams can simply integrate with an API that does all the heavy lifting including code generation, delivery, and verification as a managed service.
This way, teams won’t have to manage infrastructure by making API calls, allowing them to reduce time and effort that would otherwise be needed to launch and operate OTP flows.
Here’s just a few of the ways APIs can help offload that burden:
Faster implementation
Perhaps one of the biggest advantages of verification APIs is speed.
With verify APIs, teams no longer need to spend a considerable amount of time building OTP from scratch. Teams can integrate with a provider in a matter of days. Most APIs offer simple endpoints to send and verify codes, along with SDKs and documentation that streamline the integration process and get teams off to a quick start.
This allows teams to focus on their core functions and build a better user experience rather than backend infrastructure, accelerating time-to-market.
Global SMS routing
Many verification APIs take on the complexity of global SMS delivery.
OTP providers typically maintain strong relationships with multiple carriers and aggregators across regions to route messages efficiently based on destination, which means teams don’t have to navigate the complex web of global telecommunications regulations.
This helps take away from the fragmented nature of the SMS ecosystem, enabling more consistent and reliable delivery without requiring in-house expertise.
Built-in fraud detection
Advanced verifications APIs analyze patterns and detect anomalies in verification processes and have built-in mechanisms to protect against fraud and abuse.
For example, the API may automatically flag or block suspicious phone numbers, multiple failed attempts, or unusual request patterns.
By embedding these safeguards into the platform, OTP providers reduce the risk of abuse without requiring in-house teams to build their own fraud detection tools.
In more advanced cases, these systems can distinguish between legitimate users and fraudulent behavior using a combination of signals such as request patterns, device characteristics, and historical activity.
Given how quickly fraud-related costs can accumulate, having built-in anti-fraud mechanisms can significantly reduce risk by allowing potential threats to be identified and often stopped before they even happen.
Reliability and redundancy
Reliability is typically an integral feature of systems built by OTP providers.
To optimize delivery rates, many APIs use multiple providers or a multi-routing strategy, automatically handling failover if a delivery path underperforms. This helps ensure messages are still successfully delivered even when particular providers or routes face issues.
Some APIs also incorporate multi-channel fallback so that if one channel fails, such as SMS, the OTP can still be sent to a user’s email or WhatsApp.
With this, teams benefit from higher reliability without needing to build or maintain their own fallback logic.
The Fragmented Verification Stack Problem: Where Verification APIs Fall Short
While verification APIs reduce complexity, they still come with their own limitations, especially as products scale and requirements become more complex.
APIs may solve the initial problem but they don’t fully address the need for control, visibility and optimization. As a result, teams start to run into issues that require additional workarounds or internal tooling making things all the more complicated
Single provider dependency
Most verifications APIs operate as a single-provider abstraction, which means that teams rely on one provider’s routing decisions, pricing and regional performance. This limits the ability to optimize delivery paths or switch dynamically based on cost.
This lack of control becomes all the more pronounced as traffic scales or expands globally.
Limited visibility into delivery performance
Teams are often provided with limited view into delivery status with little visibility into what happens beyond message submission.
This makes it difficult to determine issues related to delays, carrier filtering or regional performance degradation. Without such detailed insights, teams are going in blind and relying on incomplete data to be able to effectively address user-facing issues.
Generic fraud protection
While many APIs have built-in fraud detection, these systems are usually designed for broad or more common use cases.
In other words, they may not fully detect product- or region- specific attacks or more sophisticated attacks, leaving gaps in protection. As fraud tactics evolve, especially in the age of AI, teams need more advanced solutions than what standard APIs offer.
Poor multi-region optimization
Although APIs offer global coverage, delivery performance is not actually consistent across regions.
Without the ability to fine-tune routing or leverage multiple providers, teams may struggle to achieve optimal delivery rates, latency, or cost efficiency in specific markets. This may affect delivery success rates, latency and costs, which vary depending on geography, carrier behavior, and routing paths.
The result is inconsistent performance, where verification works seamlessly in some regions but fails in others.
The fragmented verification stack
As a result of the above and to address these gaps, teams will begin to layer additional components on top of their initial API integration.
What starts as a simple setup gradually evolves into a fragmented stack that includes:
multiple SMS providers for coverage and redundancy
internal routing logic to optimize delivery and cost
separate fraud prevention tools to fill protection gaps
custom dashboards to monitor performance and KPIs
What initially started as a way to save cost, time and resources by relying on a provider instead ends up recreating many of the same challenges as building in-house.
Over time, teams find themselves faced with operating a system that is just as complex as managing their own infrastructure in-house but far more fragmented.
The initial simplicity is eventually replaced by a growing stack of interconnected tools, each solving a specific problem but altogether adding a new layer of complexity.
What Teams Actually Need (But Rarely Get)
As businesses’ requirements evolve and scale, their needs when it comes to OTP systems become clearer. Ultimately, teams seek reliability, control, visibility, and protection against fraud.
While these needs are justified, getting them all at once is another challenge entirely.
What teams actually need
To operate OTP systems reliably and at scale, teams require:
Multi-provider support to avoid single points of failure
Intelligent routing to optimize delivery based on cost, region and performance
Built-in fraud protection that continuously adapts to evolving attacks
Unified observability with visibility into delivery rates and failures
Global coverage without the burden of negotiating and managing multiple providers
Why this is actually hard to achieve: The tradeoff reality
The reality is that these capabilities rarely exist in just one solution, leaving teams having to assemble them themselves from combining providers and building routing logic to integrating anti-fraud tools and creating their own dashboards to monitor issues in real-time.
Consequently, teams are left to manage a distributed system of providers, tools and internal logic.
At this point, teams are forced to make hard choices and tradeoffs:
Optimize for simplicity and lose control
Optimize for cost and introduce complexity
Optimize for reliability and take on operational overload
Most teams end up somewhere in the middle: managing a partially optimized system but is increasingly fragmented. What looked like a simple decision of choosing a verification provider eventually turns into a much more daunting task.
The challenge, then, is not just implementing OTP verification. It’s finding a way to meet these requirements without introducing fragmentation, operational overhead, and long-term complexity.
Comparison: Build vs Buy
Build or buy, both approaches have the same end goal, which is to identify users quickly and reliably. However, they differ significantly in how that outcome is achieved and sustained over time.
Dimension | Build In-House | Buy (Verification API) |
Time to launch | Slow — requires designing and building full system infrastructure | Fast — API-based integration in days or weeks |
Initial complexity | High — OTP generation, routing, delivery, retries, fraud all built internally | Low — handled by provider |
Ongoing maintenance | Continuous engineering effort required | Minimal maintenance |
Control over system | Full control over routing, logic, and data | Limited to provider’s abstraction |
Global SMS delivery | Must manage carriers, routing logic, and regional constraints | Handled by provider |
Reliability engineering | Fully owned (failovers, redundancy, incident response) | Abstracted via provider SLAs and infrastructure |
Fraud & abuse prevention | Must be built and continuously updated | Built-in baseline protections |
Observability | Requires building dashboards and monitoring systems | Typically included out of the box |
Scalability | Requires continuous infrastructure investment | Scales automatically with usage |
Cost structure | High fixed + variable engineering + infrastructure costs | Usage-based pricing |
Vendor dependency | None, but replaced by internal ownership burden | Single-provider dependency |
Flexibility | Very high — fully customizable | Moderate — constrained by API capabilities |
Operational overhead | High — multiple systems and components to manage | Low — centralized via provider |
Questions to Ask Before Deciding
Instead of thinking of this as a binary “build vs buy” decision, it helps to evaluate your readiness across a few key dimensions.
Answering these questions can help clarify whether your team should build in-house or use a verification provider.
OTP Build vs Buy Readiness Quiz
For each question, choose the option that best reflects your current situation.
1. How critical is OTP to your core product experience?
A. It is central to user journeys and directly impacts conversion or revenue
B. It is important, but primarily functional (e.g. login, account access)
C. It is a supporting feature with minimal product differentiation impact
2. How would you describe your current infrastructure capability?
A. We already operate distributed, high-availability systems at scale
B. We have strong backend systems but limited experience with global delivery infrastructure
C. We do not currently manage infrastructure of this complexity
3. How important is full control over routing, delivery, and logic?
A. We need full control and customization across the stack
B. We need some flexibility but can accept abstractions
C. We prefer not to manage infrastructure-level decisions
4. How important is global delivery consistency across regions?
A. Critical — we operate globally and need optimized performance per region
B. Important, but occasional variation is acceptable
C. Not a primary concern for our use case
5. Do you have the capacity to own ongoing operational complexity?
A. Yes — we can support continuous monitoring, maintenance, and optimization
B. Partially — but we would prefer to minimize operational burden
C. No — we need a managed solution
6. How comfortable are you managing multiple vendors and systems?
A. We already manage multiple providers and are comfortable adding more
B. We prefer to minimize vendor complexity where possible
C. We want a single integrated solution
How to interpret your answers
Mostly A’s → You likely benefit from building in-house or deeply customizing infrastructure
Mostly B’s → You are in a hybrid zone, where APIs help but may not fully solve your needs
Mostly C’s → A verification API or managed solution is likely the best fit
No matter what your current situation is, one thing becomes clear over time: verification doesn’t stay simple for long, resulting in a fragmented system that must be actively managed and maintained.
From Fragmentation to Reliability: End-to-End Verification in One Platform
At this point, one thing is certain: OTP verification is not just a feature, it’s a system that requires coordination across multiple providers, routing logic, fraud protection and observability.
The real challenge, then, isn’t sending OTPs but operating the system behind them.
Solving the fragmentation problem
Most modern verification systems take a fundamentally different approach in that they no longer force teams to resort to assembling and managing multiple fragmented components.
Instead, they offer verification as a unified layer, where routing, redundancy, fraud protection, and observability are built into a single system.
The goal is not only to simplify implementation but also to eliminate the operational burden that comes with these systems.
End-to-End Verification, Built for Teams in One Platform
By the time teams reach scale, previously silent failures and hidden inefficiencies begin to surface.
Teams find themselves juggling multiple providers, managing routing logic, implementing fraud prevention, and building custom dashboards for monitoring.
What should be simple turns into a system that requires constant attention.
Prelude was built to remove that complexity entirely.
Prelude replaces this fragmented approach with a single system, one that handles routing, reliability, fraud protection, and observability.
Rather than assembling and managing all these components separately, teams can now rely on a system where everything works seamlessly together by design.
Multi-provider infrastructure, without the overhead
Prelude gives you access to multiple SMS providers globally by partnering with many providers to guarantee the highest possible delivery rate at the lowest possible cost, without needing to source, integrate or manage them individually yourself.
This means:
No vendor sourcing or procurement
No custom routing logic to build or maintain
Built-in redundancy across providers
What typically takes months to build is available right away out of the box.
Real-time routing and reliability
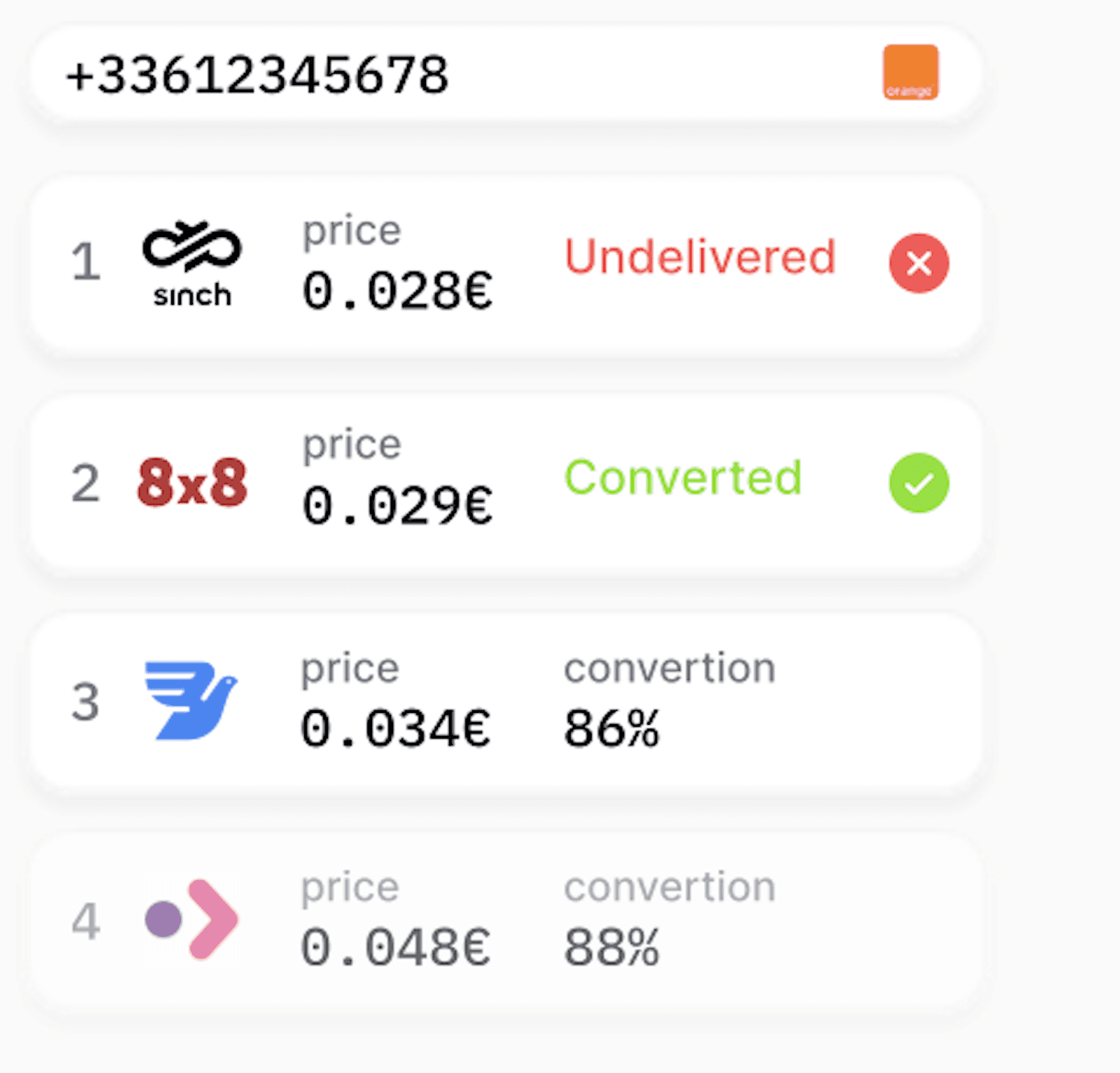
Prelude continuously monitors delivery performance for you and dynamically routes traffic to ensure high success rates.
Routing is handled automatically thanks to our routing engine which compares all available routes and selects the best one for each individual user.
If a provider underperforms or fails, traffic is automatically redirected without any impact on the user experience.
The golden metric: Beyond delivery rates
While tracking SMS delivery rates should be a priority, it’s not the only metric you should be focusing on.
Most OTP systems will focus on the initial step of the authentication process but overlook the next step, which is just as, if not more, important.
The real goal should be to measure conversion. In other words, how many users who received an OTP actually took the desired action as a result of this SMS?
Prelude's Verify API prioritizes time and conversion by dynamically routing users to the cheapest channel most likely to convert.
Built-in fraud protection
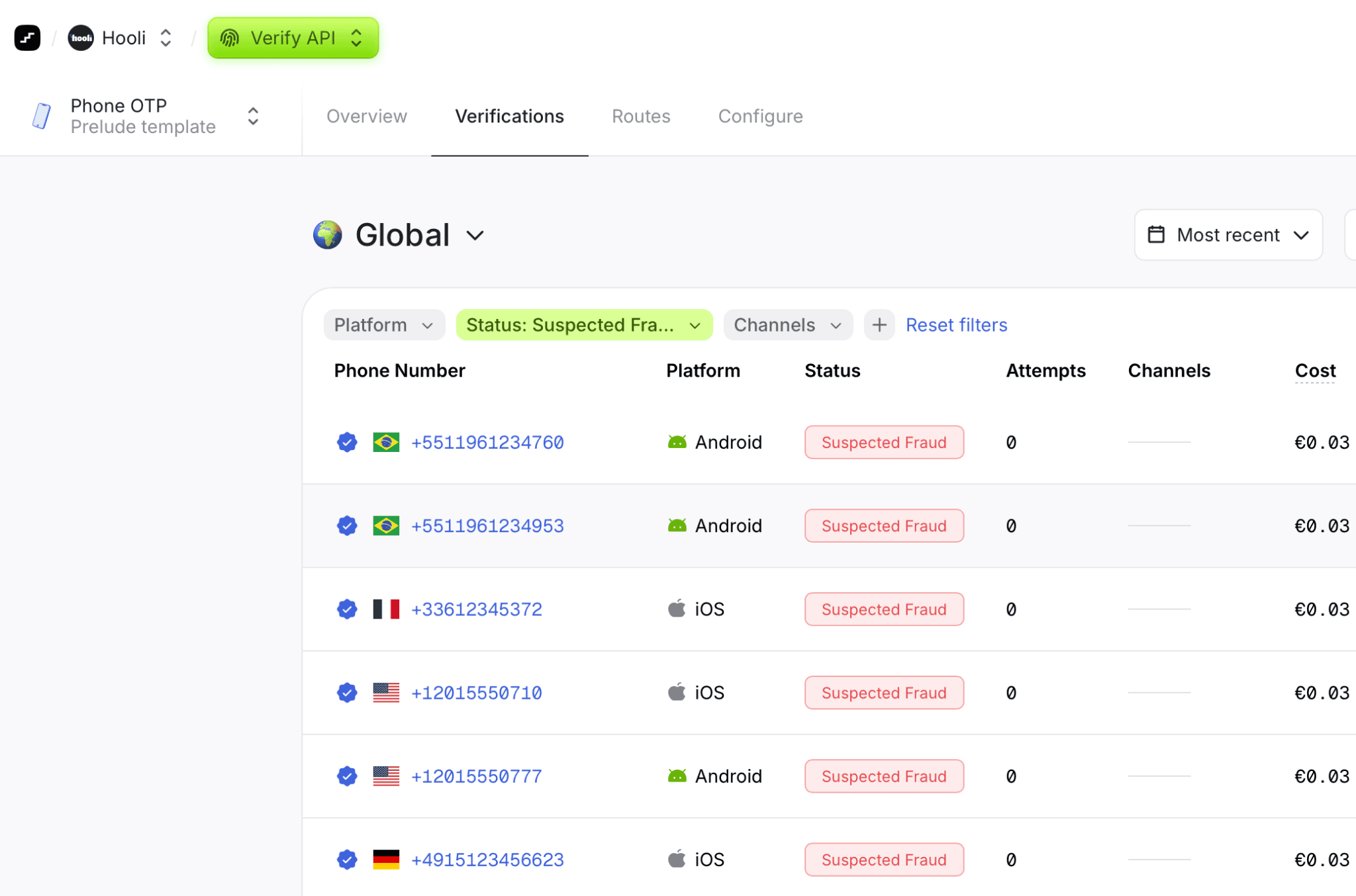
While many solutions offer anti-fraud features as an optional add-on, fraud detection is integrated directly into Prelude’s verification flow.
Our solution detects suspicious behavior in real-time by utilizing dozens of signals relating to each verification and draws on data from our vast database to predict whether a request is likely to be fraudulent.
The Prelude system continually learns from new fraud patterns in order to adapt to new attack vectors while granularly filtering the attacker from real users without resorting to blocking an entire country or network block.
No additional teams or integrations are required.
Unified visibility across your entire system
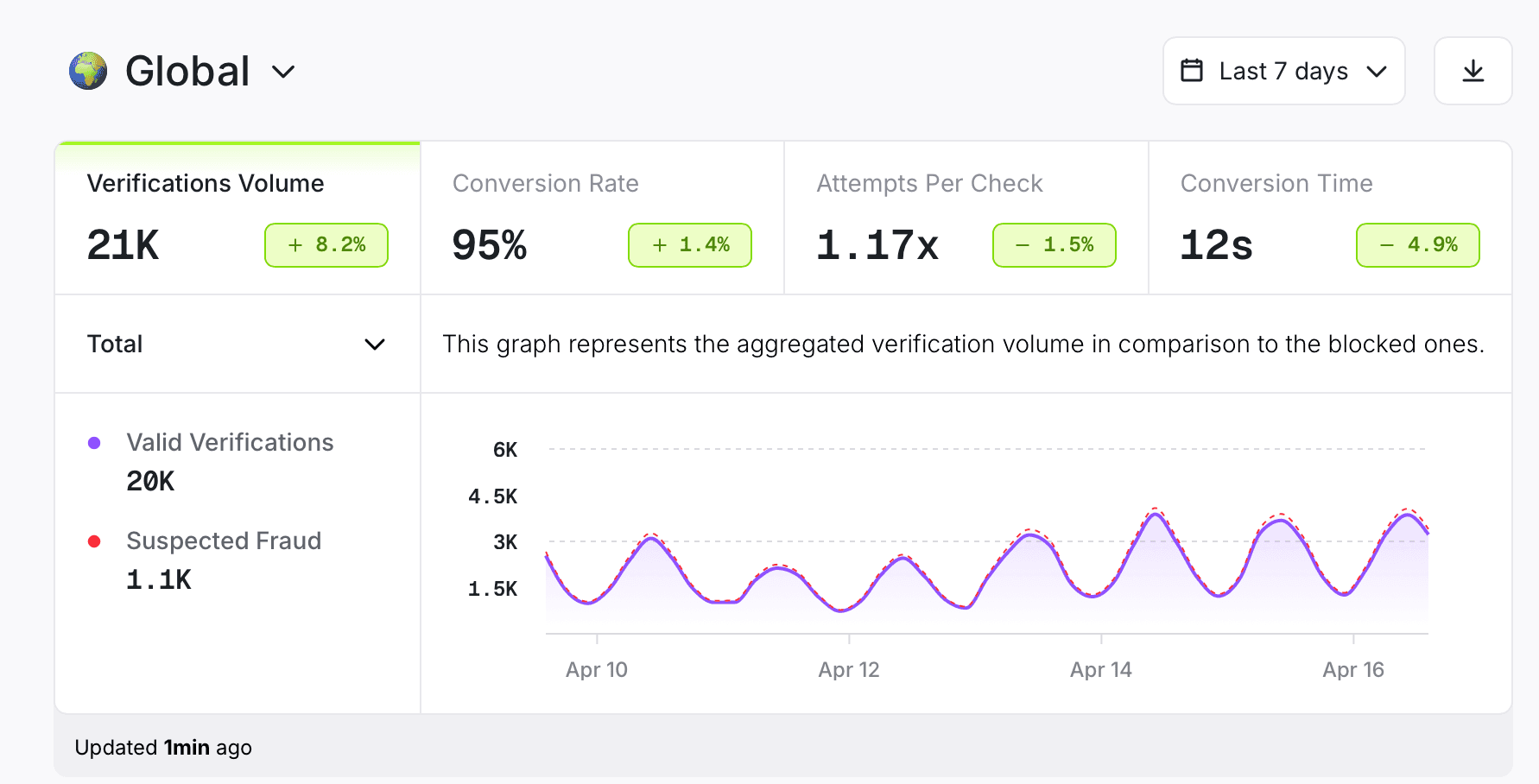
Prelude provides full visibility including real-time insights and alerting into your verification system, all in one place. This enables teams to track performance across regions, providers and delivery rates so they can track and quickly detect issues and optimize performance without having to build a custom dashboard themselves.
Cost optimization built into authentication
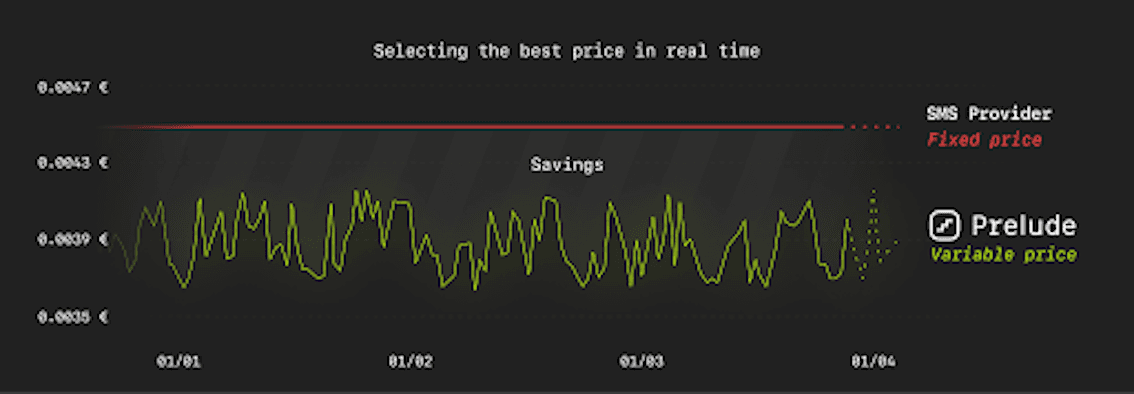
OTP costs quickly escalate due to high SMS pricing, fraud traffic, inefficient routing, and repeated retries caused by poor deliverability.
By combining intelligent routing, built-in fraud prevention, and optimized delivery paths, Prelude reduces unnecessary message volume and ensures each OTP is delivered as efficiently as possible. In cases where SMS is not the most effective channel, alternative delivery methods can be leveraged to further optimize cost and performance.
Instead of treating cost as a byproduct, Prelude makes it a controllable part of the system, delivering immediate and scalable cost savings.
From Complexity to Reliability
With Prelude, teams no longer have to juggle multiple providers, build and maintain routing systems, integrate fraud tools or create monitoring dashboards.
Instead, verification becomes infrastructure, one that is reliable, scalable and managed by design.
We do the heavy lifting so you can achieve:
Faster time to market by launching immediately without building infrastructure
Higher reliability with built-in redundancy and intelligent routing
Lower operational overhead since there’s no fragmented stack to manage
Better visibility with real-time insights across the system
Stronger protection with fraud prevention embedded by default
Conclusion
OTP verification doesn’t have to be a fragmented system.
The key is choosing the right approach, one that turns verification into infrastructure so teams can focus on building their core product, not maintaining the systems behind it.
The real question has to do with ownership and whether you want to build and operate your own system while managing the tradeoffs that come with it or rely on infrastructure that removes the burden altogether?
When it comes down to it, it’s not about how quickly you can implement verification but how effectively you can scale and operate it over time.
At the end of the day, sending OTPs is simple. Operating the system behind them is not.
Prelude was especially built to remove that burden by turning verification into reliable, scalable infrastructure so your team can focus on building their core product. Book a demo today and see it in action.
FAQs
What is an OTP verification system?
An OTP (One-Time Password) verification system is an authentication method used to verify a user’s identity by sending a temporary code via SMS, email, or app. OTP systems are widely used for login authentication, two-factor authentication (2FA), and account security in modern applications.
Why is building an OTP system complex?
Building an OTP system is complex because it requires more than sending a code. It involves distributed system architecture, SMS delivery infrastructure, retry and fallback logic, fraud detection, rate limiting, and global carrier integration. At scale, OTP systems must also handle latency, failures, and traffic spikes reliably.
When should you build an OTP system in-house?
You should consider building an OTP system in-house when you have strong infrastructure and security engineering capabilities, strict compliance requirements, or when authentication is a core part of your product. Teams operating at large scale may also benefit from building for greater control over performance and optimization.
What are the risks of building an OTP system internally?
The main risks of building an internal OTP system include high infrastructure complexity, ongoing maintenance overhead, security vulnerabilities, and fraud exposure. OTP systems require continuous monitoring and updates, and failures can directly impact user experience, login success rates, and trust.
What is SMS OTP fraud or SMS pumping?
SMS pumping is a type of fraud where attackers trigger large volumes of OTP messages to generate revenue or exploit messaging costs. This can lead to unexpected financial losses and increased infrastructure costs. SMS OTP systems are also vulnerable to bot-driven attacks and number recycling abuse.
How do OTP verification APIs work?
OTP verification APIs simplify authentication by providing pre-built infrastructure for sending and validating OTP codes. They typically include global SMS delivery, basic fraud detection, and retry handling. These APIs allow companies to implement OTP authentication quickly without building infrastructure from scratch.
What are the limitations of OTP verification APIs?
OTP verification APIs can introduce limitations such as dependency on a single provider, limited control over routing and delivery optimization, lack of deep observability, and generic fraud protection. At scale, these constraints can impact performance, cost efficiency, and reliability.
Why do OTP systems become fragmented at scale?
OTP systems often become fragmented as companies scale because they add multiple SMS providers for redundancy, build internal routing logic, integrate separate fraud detection tools, and create custom dashboards for monitoring. This leads to a complex, distributed verification stack that is harder to maintain.
What is the best approach to OTP authentication for scaling companies?
For scaling companies, the best approach depends on infrastructure maturity and product requirements. Many teams start with verification APIs for speed, but as they grow, they often need better control, observability, and multi-provider reliability. A unified verification infrastructure helps reduce complexity while maintaining global performance and security.
Building or buying software is a decision every product and engineering team faces, regardless of company size or stage. When it comes to authentication, and specifically OTP verification, this choice becomes even more critical.
With AI tools accelerating development, the barrier to building software has never been lower with teams assembling systems faster than ever before. However, while AI makes it easier to write code, it doesn’t eliminate the complexity of running systems in production, especially for those that require high reliability, security and global performance.
At first glance, building an OTP system seems straightforward enough. Whatever choice you make when it comes to your authentication process will not only have major security implications but also will affect user experience, engineering bandwidth, and the long-term cost of maintaining the system.
You may consider building your own OTP flows but teams often underestimate the complexities that come with it. After all, how complex can sending a 6-digit code be? In practice, what appears simple quickly becomes a distributed systems problem, one that involves message delivery optimization, retry logic, fraud prevention and global infrastructure considerations.
The stakes are also unusually high as authentication systems handle high volumes of personal and sensitive user data, making them a prime target for abuse and attacks which could lead to security breaches, degraded user trust and lasting reputational damage. According to a report by CrowdStrike, AI-driven attacks have surged by 89% over the past year alone, with breakout times now averaging just 29 minutes, allowing attackers to move from initial access to impact faster than ever.
That level of risk is also why the build vs buy decision matters more than ever.
As a general rule, if it’s not part of your core product, it’s worth reconsidering whether to build it yourself. Because for most teams, the real challenge isn’t implementing OTP, it’s actually operating it reliably at scale.
What an OTP Verification System Actually Includes
At first glance, SMS OTP flows seem straightforward: a user requests access to a system, receives an OTP code to their device, enters it and they’re in. The concept in itself is simple but its implementation is more complex that teams actually anticipate.
In reality, that simple interaction sits on top of a system that has to generate, securely deliver and validate those codes, often across various regions and networks.
OTP verification is more than just sending a message. What happens behind the scenes, including how the code is created, delivered and validated, is far more complicated. The real challenge is doing this safely and at scale.
Core components of an OTP verification system
OTP Generation
An OTP system begins with code generation but even that is more nuanced than it appears.
The ultimate goal of any SMS OTP system is to ensure that only the right user gets the code and that this code is:
Works just one time
Expires within a quick time frame
Is delivered correctly and quickly, even during traffic spikes
Resists attacks
The system must then manage its entire lifecycle, from its generation, validity period to its expiration.
Without careful lifecycle management, systems can become vulnerable to replay attacks or lead to a poor user experience.
Secure Storage
Once generated, the code must be securely stored to prevent exposure, often through hashing or encryption.
This is especially critical as authentication systems are a prime target for attackers so it’s essential to enforce strict validation rules during verification as any small weakness in how codes are validated or stored can be exploited.
SMS Routing and Delivery Optimization
Delivery introduces another layer of complexity. Performance varies significantly depending on region, carriers and routing decisions.
Ensuring that a message reaches a user quickly and reliably often requires dynamic routing logic, awareness of regional constraints, and the ability to adapt to inconsistent carrier behavior.
What works well in one country or region may fail silently in another.
Retry and Fallback Logic
Even with routing optimized, successful delivery is never a guarantee. Messages can be delayed or fail to reach their destination altogether, which makes retry and fallback logic critical.
A well-designed system must be able to determine when to resend a code without overwhelming the user and how to handle the in-between, that is a delayed OTP that arrives after a newer code has already been sent. The system should efficiently handle delays and resends including having a limit on the number of resends and always invalidate old OTPs if a new one is re-sent to keep the authentication process secure.
Furthermore, a robust OTP system should not rely on a single delivery path. It needs to have automated fallback mechanisms that can switch to another provider or an alternate channel. This means that if a primary route is degraded or unavailable, the system should seamlessly reroute messages through an alternative provider or fail over to another channel altogether.
Otherwise, delivery failures become single points of failure which directly impact login success rates and user trust, thereby negatively impacting conversion rates.
Rate Limiting and Abuse Prevention
At the same time, SMS OTP systems must continuously defend against a wide range of attacks. One common threat is SMS pumping, where attackers generate large volumes of OTP requests to premium-rate numbers or specific regions, driving up messaging costs. In parallel, there are brute-force attempts where attackers repeatedly try different code combinations to gain unauthorized access. There are just a couple of the many ways OTP endpoints can be exploited. .
Because these attacks often mimic legitimate traffic, they can go undetected until costs have already escalated, turning such systems into a cost liability.
Addressing such risks require advanced approaches, such as pattern recognition, anomaly detection and behavioral analysis to distinguish between legitimate and malicious activity.
As attack methods evolve, these safeguards need continuous tuning, making fraud and abuse an ongoing effort that requires constant adaptation.
Monitoring and analytics
It’s important to have high-level visibility to make sure that messages are being delivered and determine whether there are delays and where failures occur.
A robust OTP system should allow you to monitor key metrics such as delivery rates, latency and failure patterns. Centralized dashboards, combined with real-time alerting, allow teams to detect and respond to issues before they impact users at scale. Without this level of visibility, failures go unnoticed until they affect user trust or conversion.
Having continuous and real-time observability is the best way to optimize the performance of an OTP system.
Quick check: What a reliable OTP system actually requires
✔ Can we securely generate, store, and expire OTPs correctly?
✔ Do we handle OTP lifecycle (validation, invalidation, edge cases)?
✔ Are messages routed and optimized for global delivery?
✔ Do we have retry and fallback logic if delivery fails?
✔ Have we implemented rate limiting and abuse prevention?
✔ Do we have visibility into delivery, latency, and failures?
When it Makes Sense to Build an SMS OTP System In-House
After looking in-depth at what an OTP system actually looks like, a lot of teams may decide it’s not worth the hassle. However, there are specific scenarios where building your own OTP system can be a justified choice.
Quick check: Should you build OTP in-house?
Do we have a mature infrastructure and security team?
Do we require full control over data and compliance?
Are we operating at a scale where optimization matters?
Is OTP central to our product experience or conversion?
Are we prepared to maintain and evolve this system long-term?
If you answered yes to most of these questions then you’re on the right track to building your own system. Let’s take a deeper look at what it all entails.
You have a mature infrastructure and security team
As we’ve seen, OTP systems are not standalone features. OTP verification may appear lightweight on the surface but in practice it relies on infrastructure that must be highly available, globally distributed, and resilient to failure.
Building and operating this kind of mature infrastructure requires teams with experience in distributed systems, reliability engineering, security and large-scale backend systems along with dedicated teams who can monitor system health, respond to incidents and continuously optimize performance. Even small disruptions in delivery or latency can directly impact user experience, making reliability a core requirement rather than an afterthought.
Additionally, OTP systems are a frequent target for fraud and abuse. If you choose to build then that means taking full responsibility for securing the entire flow. This requires not only implementing safeguards, but also continuously evolving them as attack patterns change.
Finally, the work that goes into OTP systems doesn’t end once the system is built. It requires ongoing maintenance, monitoring and iteration. Organizations that already operate similar systems such as messaging platforms or authentication services are better positioned to handle such complexity.
You need full control over data and compliance
Building in-house makes sense when you need full control over data and compliance. This is particularly relevant for organizations within the financial, healthcare or government industries that often operate under strict regulatory requirements around how data is stored and used.
In these cases, relying on third-party providers may introduce risks or constraints, particularly if those providers can’t guarantee how and where data is processed.
On the one hand, maintaining full ownership of the authentication flow makes it easier for these organizations to meet internal security standards, pass compliance audits, and align with regulatory frameworks.
On the other hand, this level of control comes with added responsibility. Teams must ensure that their implementation meets all relevant security and regulatory standards, and that systems are continuously updated as requirements evolve. This requires ongoing investment in both infrastructure and processes.
You operate at a very large scale
Scale is another important factor to consider when choosing whether to build your own system. When operating at a high scale, sending large volumes of OTP requests per day, organizations may choose to build in order to gain better control over how messages are routed, dynamically selecting providers based on cost, performance, or regional reliability.
In this case, organizations may benefit from directly negotiating with carriers, optimizing routing strategies, and fine-tuning performance in ways that are difficult to achieve through standard APIs.
However, these optimizations introduce a new layer of complexity. Dynamic routing requires custom logic and constant tuning. Managing multiple providers brings procurement overhead, contract negotiations, and ongoing vendor management. What begins as an effort to reduce costs can quickly evolve into an operational burden, with teams responsible for maintaining routing systems, monitoring performance, and resolving delivery issues across regions.
In addition, large-scale systems require more sophisticated infrastructure that demand robust queuing systems, efficient retry mechanism and the ability to handle sudden spikes in traffic without performance being degraded. Not to mention that products operating at a global scale must account for regional differences in carriers, regulations and network reliability which adds another level of complexity.
Operating at this level introduces new challenges as the more you scale, the more moving parts you bring including multiple providers, routing logic, performance monitoring, and cost management. Eventually, you end up with a complex system that requires its own dedicated engineering and resources to maintain long-term, which means it’s essential to consider whether the benefits of optimization outweigh the long-term costs of owning and maintaining the system.
For smaller companies, the challenge is slightly different. It’s not just scale but anticipating it. These companies often need to build systems that can grow with them but without having access to the same resources or expertise as larger organizations to build for scale. As a result, teams are forced to make tradeoffs, either investing early in more complex infrastructure than they currently need, or starting simple and risking limitations as they scale.
OTP is a core part of your product experience
For some, OTP is actually the core part of the product rather than a supporting function. For applications such as marketplaces or fintech platforms, where authentication is frequent and tied to key user actions, OTP plays a more central role, directly impacting user experience, thereby influencing conversion rates.
In such cases, teams often require a higher degree of control from optimizing delivery speed in specific regions, or tailoring verification flows based on user behavior and risk signals to smaller improvements such as increasing delivery success rates, all of which have a direct impact on user engagement and revenue.
As a result, building in-house makes sense when teams need the flexibility to deeply optimize and integrate verification into their core user flows.
Ultimately, building in-house makes sense if you’re willing to treat OTP as infrastructure rather than a one-time feature. This means fully committing to ongoing maintenance, monitoring, and iteration. Teams need to be all hands on deck and be ready to respond to any incidents, optimize performance and invest in long-term reliability.
For organizations looking for full control and flexibility, building is usually the go-to option. For everyone else, the challenge isn’t just implementing OTP but also sustaining and scaling the system over time.
What starts as a single OTP system often grows into a collection of interconnected components: multiple SMS providers for coverage and redundancy, custom routing logic to optimize delivery, separate tools for fraud prevention, and internal dashboards to track performance. Over time, teams find themselves managing not just a system, but a fragmented stack with many moving parts.
Understanding the nature of a fragmented system and the operational overhead that comes with it is key to evaluating the real cost of building your own OTP infrastructure.
The Reality of Building Your Own OTP System
Even when the decision to build in-house is justified, the operational reality is more complex than it seems. What looks like a straightforward authentication feature quickly expands into a fragmented system that must perform reliably over time and under pressure.
The fact is teams often greatly underestimate just how complex an OTP system is beneath the surface, making the build and implementation and process a bigger challenge than anticipated.
Let’s take a look at what it really takes to build your own OTP system with a few questions for you and your team to consider:
Are we prepared to manage distributed systems complexity?
Can we handle global SMS delivery across regions and carriers?
Do we have systems in place to detect and prevent fraud?
Can we reliably detect and debug silent delivery failures?
Do we have resources for ongoing maintenance and incident response?
Infrastructure complexity
An OTP system is a fragmented, distributed system problem. Every verification request has to be processed in real time under strict latency constraints while interacting with multiple external dependencies such as SMS gateways, databases, and fallback services.
This means the system must be designed to handle retries, timeouts and partial failures without duplicating messages or breaking the user flow. OTP systems must also be able to function reliably under unpredictable conditions, such as sudden traffic spikes without degradation.
Failure handling is one of the most critical aspects of this architecture. External SMS providers may experience latency, throttling, or downtime, and internal services may also fail under load. The system must be designed to effectively handle these scenarios through retries, timeouts, and fallback logic.
A further challenge is ensuring consistency across asynchronous processes. An OTP may be generated, queued, partially delivered, retried, or delayed, sometimes even arriving out of order relative to newer codes. The system must ensure that only the most recent valid code is accepted, while older codes are invalidated correctly across all states.
Observability also becomes essential at this layer. Debugging issues often requires tracing a single OTP request across multiple services and external providers, which can be difficult without unified logging and monitoring.
As a result, such systems require careful architectural planning, deep understanding of failure modes, and ongoing operational oversight to ensure consistent performance at scale.
Global SMS Delivery
Delivering SMS globally is far from uniform. It depends on a fragmented ecosystem of carriers, aggregators, and regional regulations, each with its own constraints and performance characteristics. Each country has its own carrier requirements, regulatory constraints, and delivery behaviors that directly impact delivery success rates.
For example, carrier behavior varies significantly across regions. Delivery speed, reliability and throughput can differ depending on the local network, routing paths and even time of day. This means that achieving consistent delivery often requires dynamically selecting providers or routes based on regional performance.
Consequently, teams need to maintain complex routing logic that determines how messages are delivered based on a combination of factors including geography, cost and performance. In many cases, this involves establishing strong carrier relationships and understanding regional nuances.
Plus, these conditions are not static. Carrier performance fluctuates, regulations evolve, and routing effectiveness can change over time. Ensuring reliable OTP delivery across regions requires continuous optimization, monitoring, and adaptation to local constraints.
Fraud & Abuse
OTP systems are a frequent target of attacks, many of which mimic real traffic and legitimate usage patterns. Common examples include SMS pumping, where attackers generate large volumes of messages to drive up costs, bot-driven attacks that flood verification endpoints and number recycling attacks where previously used phone numbers are exploited to gain unauthorized access.
Detecting such attacks is not so straightforward, making fraud an ongoing challenge that requires layered defenses, continuous monitoring and adaptation as attack techniques evolve.
Reliability: The Silent Failure Problem
OTP systems are expected to be highly reliable and yet achieving consistent delivery at scale is difficult in practice.
As discussed, delivery success rates vary depending on the region, carrier behavior and network conditions. There’s also the issue of messages being successfully sent but that still arrive late, out of order or not at all, creating major inconsistencies in user experience.
This means that OTP systems shouldn’t have a single point of failure. To mitigate this, systems often require redundancy, or using multiple providers or delivery paths to ensure messages are successfully delivered if one fails or underperforms. However, this will require teams to build logic to not only detect these failures but also switch providers in real-time and ensure fallback mechanisms work seamlessly without the risk of message duplication or affecting the user experience.
Such failures are more often than not silent where messages are delayed or dropped without clear error signals. Without unified visibility across providers and regions, teams often struggle to diagnose issues quickly, leading to degraded user experience and reduced conversion rates without clear root causes.
The most damaging OTP failures aren’t the ones that break but the ones you don’t notice.
Maintenance Never Stops
With providers changing their APIs, carrier behavior shifting across regions, fraud patterns evolving and infrastructure requirements growing over time, OTP systems need to be continuously monitored and updated to keep up with these changes and maintain their performance and reliability.
In addition, with issues constantly coming up, incident handling becomes a recurring responsibility. This means teams need to be well-prepared to respond to delivery outages, investigate anomalies and implement fixes under strict time constraints.
Over time, a simple authentication feature quickly turns into a system that requires dedicated ownership and long-term engineering resources.
The True Cost of Building OTP Infrastructure
While the build approach can bring many benefits including full control and ownership of the solution as well as potentially save costs usually associated with third-party solutions, the trade-offs can be significant.
Teams must now spend significant time and effort on not just building the solution but also maintaining it long-term, which may divert their attention from their core operations.
Moreover, the gap between implementing OTP and operating it reliably at scale is significant and the complex nature of these systems doesn’t only impact engineering but also directly drives long-term costs.
One of the most common misconceptions about building OTP systems in-house is that the primary cost is technical, focused on SMS pricing and infrastructure. While those cost considerations are valid and significant, the total costs extend beyond what is actually visible.
While direct costs are relatively easy to estimate, the hidden and ongoing operational costs are often what make building significantly more expensive over time.
Direct Costs
At a baseline level, OTP systems incur direct, measurable costs.
The most obvious one is SMS spend. Each OTP sent carries a per-message cost, which varies depending on destination, carrier and routing path. As OTPs increase in volume, costs can quickly become substantial, especially in regions with high messaging fees.
There are also costs associated with running the system itself. This includes compute resources, databases for storing OTPs and session data, queuing systems for handling traffic, and monitoring tools to track system performance.
However, these costs only represent a portion of the investment required to operate these systems.
Hidden Costs
Engineering time
An OTP system requires continuous maintenance, optimization and troubleshooting beyond initial implementation. This includes defining routing logic, improving delivery rates, updating integrations with providers, and responding to performance issues.
Due to its complexity, an OTP infrastructure becomes a recurring engineering commitment rather than a one-time effort.
Opportunity cost
Any time spent on building and maintaining OTP systems is time not spent on core product development.
As mentioned earlier, teams must now spend substantial time maintaining the system and responding to incidents at any moment’s notice. For teams where authentication is not a core, differentiating feature, building in-house takes away from engineering resources from higher-impact initiatives such as product innovation, growth features or user experience improvements.
This tradeoff is often underestimated yet its impact is significant, particularly in fast-moving organizations where speed to market is critical.
Incident recovery
OTP systems directly affect user access, which means any failures can have immediate (and negative) impact. When issues occur, such as delivery or provider outages, teams must quickly address these issues to minimize disruption.
Incident response usually requires cross-functional efforts, including debugging across multiple systems and external providers.
Therefore, these situations are time-sensitive, unpredictable and require ample resources, which further adds to the operational burden over time.
Procurement and vendor management
Beyond technical implementation, teams must also take into account the responsibility of managing external providers.
This includes sourcing SMS vendors, negotiating contracts, monitoring pricing changes, and maintaining relationships across regions. For teams using multiple providers to ensure coverage and redundancy, this overhead increases significantly.
These procurement and vendor management efforts are rarely accounted for upfront, yet they introduce ongoing complexity and cost that scale with the system.
The real cost of an OTP system extends beyond just sending that message. It's all the costs of operating, maintaining and updating the system over time.
Build vs Buy: Cost Breakdown Comparison
Cost Category | Build In-House | Buy (OTP Provider) |
SMS / Usage Costs | Direct carrier or aggregator pricing (can optimize at scale, but requires effort) | Pay-per-use pricing, typically bundled with delivery optimization |
Infrastructure | Hosting, databases, queues, monitoring systems | Included in provider pricing |
Initial Engineering | High upfront cost to design, build, and integrate system | Low - API integration typically takes days to weeks |
Ongoing Engineering | Continuous maintenance, optimization, and updates | Minimal—handled by provider |
Opportunity Cost | High - engineering time diverted from core product | Low - teams focus on product development |
Fraud & Abuse Prevention | Requires building and maintaining detection systems | Often built-in or partially handled |
Reliability Engineering | Internal responsibility (failover, retries, monitoring) | Managed by provider (SLAs, redundancy) |
Multi-Provider Management | Required for redundancy and optimization | Not required (or abstracted away) |
Procurement & Negotiation | High - vendor sourcing, contracts, pricing negotiations | None - single vendor relationship |
Vendor Management | Ongoing coordination across multiple providers | Minimal |
Global Compliance | Internal responsibility (regulations, sender IDs, registration) | Typically handled or guided by provider |
Observability & Analytics | Must build dashboards, alerts, and reporting | Often included out-of-the-box |
Incident Response | Fully owned internally | Shared or handled by provider |
Time to Market | Slow - weeks to months | Fast - days to weeks |
Scalability Costs | Requires ongoing infra and architecture investment | Scales with usage |
How Verifications APIs work (And Where They Help)
Given the complex nature of OTP systems, many businesses opt for verification APIs to simplify implementation and offload operational burden.
Verify APIs enable businesses to verify phone numbers and/or email addresses. They take on managing the full verification lifecycle, from initiating the verification, sending OTP messages and performing retries, to checking the validity of the OTP code and returning the result.
In that sense, instead of building and maintaining the full system, teams can simply integrate with an API that does all the heavy lifting including code generation, delivery, and verification as a managed service.
This way, teams won’t have to manage infrastructure by making API calls, allowing them to reduce time and effort that would otherwise be needed to launch and operate OTP flows.
Here’s just a few of the ways APIs can help offload that burden:
Faster implementation
Perhaps one of the biggest advantages of verification APIs is speed.
With verify APIs, teams no longer need to spend a considerable amount of time building OTP from scratch. Teams can integrate with a provider in a matter of days. Most APIs offer simple endpoints to send and verify codes, along with SDKs and documentation that streamline the integration process and get teams off to a quick start.
This allows teams to focus on their core functions and build a better user experience rather than backend infrastructure, accelerating time-to-market.
Global SMS routing
Many verification APIs take on the complexity of global SMS delivery.
OTP providers typically maintain strong relationships with multiple carriers and aggregators across regions to route messages efficiently based on destination, which means teams don’t have to navigate the complex web of global telecommunications regulations.
This helps take away from the fragmented nature of the SMS ecosystem, enabling more consistent and reliable delivery without requiring in-house expertise.
Built-in fraud detection
Advanced verifications APIs analyze patterns and detect anomalies in verification processes and have built-in mechanisms to protect against fraud and abuse.
For example, the API may automatically flag or block suspicious phone numbers, multiple failed attempts, or unusual request patterns.
By embedding these safeguards into the platform, OTP providers reduce the risk of abuse without requiring in-house teams to build their own fraud detection tools.
In more advanced cases, these systems can distinguish between legitimate users and fraudulent behavior using a combination of signals such as request patterns, device characteristics, and historical activity.
Given how quickly fraud-related costs can accumulate, having built-in anti-fraud mechanisms can significantly reduce risk by allowing potential threats to be identified and often stopped before they even happen.
Reliability and redundancy
Reliability is typically an integral feature of systems built by OTP providers.
To optimize delivery rates, many APIs use multiple providers or a multi-routing strategy, automatically handling failover if a delivery path underperforms. This helps ensure messages are still successfully delivered even when particular providers or routes face issues.
Some APIs also incorporate multi-channel fallback so that if one channel fails, such as SMS, the OTP can still be sent to a user’s email or WhatsApp.
With this, teams benefit from higher reliability without needing to build or maintain their own fallback logic.
The Fragmented Verification Stack Problem: Where Verification APIs Fall Short
While verification APIs reduce complexity, they still come with their own limitations, especially as products scale and requirements become more complex.
APIs may solve the initial problem but they don’t fully address the need for control, visibility and optimization. As a result, teams start to run into issues that require additional workarounds or internal tooling making things all the more complicated
Single provider dependency
Most verifications APIs operate as a single-provider abstraction, which means that teams rely on one provider’s routing decisions, pricing and regional performance. This limits the ability to optimize delivery paths or switch dynamically based on cost.
This lack of control becomes all the more pronounced as traffic scales or expands globally.
Limited visibility into delivery performance
Teams are often provided with limited view into delivery status with little visibility into what happens beyond message submission.
This makes it difficult to determine issues related to delays, carrier filtering or regional performance degradation. Without such detailed insights, teams are going in blind and relying on incomplete data to be able to effectively address user-facing issues.
Generic fraud protection
While many APIs have built-in fraud detection, these systems are usually designed for broad or more common use cases.
In other words, they may not fully detect product- or region- specific attacks or more sophisticated attacks, leaving gaps in protection. As fraud tactics evolve, especially in the age of AI, teams need more advanced solutions than what standard APIs offer.
Poor multi-region optimization
Although APIs offer global coverage, delivery performance is not actually consistent across regions.
Without the ability to fine-tune routing or leverage multiple providers, teams may struggle to achieve optimal delivery rates, latency, or cost efficiency in specific markets. This may affect delivery success rates, latency and costs, which vary depending on geography, carrier behavior, and routing paths.
The result is inconsistent performance, where verification works seamlessly in some regions but fails in others.
The fragmented verification stack
As a result of the above and to address these gaps, teams will begin to layer additional components on top of their initial API integration.
What starts as a simple setup gradually evolves into a fragmented stack that includes:
multiple SMS providers for coverage and redundancy
internal routing logic to optimize delivery and cost
separate fraud prevention tools to fill protection gaps
custom dashboards to monitor performance and KPIs
What initially started as a way to save cost, time and resources by relying on a provider instead ends up recreating many of the same challenges as building in-house.
Over time, teams find themselves faced with operating a system that is just as complex as managing their own infrastructure in-house but far more fragmented.
The initial simplicity is eventually replaced by a growing stack of interconnected tools, each solving a specific problem but altogether adding a new layer of complexity.
What Teams Actually Need (But Rarely Get)
As businesses’ requirements evolve and scale, their needs when it comes to OTP systems become clearer. Ultimately, teams seek reliability, control, visibility, and protection against fraud.
While these needs are justified, getting them all at once is another challenge entirely.
What teams actually need
To operate OTP systems reliably and at scale, teams require:
Multi-provider support to avoid single points of failure
Intelligent routing to optimize delivery based on cost, region and performance
Built-in fraud protection that continuously adapts to evolving attacks
Unified observability with visibility into delivery rates and failures
Global coverage without the burden of negotiating and managing multiple providers
Why this is actually hard to achieve: The tradeoff reality
The reality is that these capabilities rarely exist in just one solution, leaving teams having to assemble them themselves from combining providers and building routing logic to integrating anti-fraud tools and creating their own dashboards to monitor issues in real-time.
Consequently, teams are left to manage a distributed system of providers, tools and internal logic.
At this point, teams are forced to make hard choices and tradeoffs:
Optimize for simplicity and lose control
Optimize for cost and introduce complexity
Optimize for reliability and take on operational overload
Most teams end up somewhere in the middle: managing a partially optimized system but is increasingly fragmented. What looked like a simple decision of choosing a verification provider eventually turns into a much more daunting task.
The challenge, then, is not just implementing OTP verification. It’s finding a way to meet these requirements without introducing fragmentation, operational overhead, and long-term complexity.
Comparison: Build vs Buy
Build or buy, both approaches have the same end goal, which is to identify users quickly and reliably. However, they differ significantly in how that outcome is achieved and sustained over time.
Dimension | Build In-House | Buy (Verification API) |
Time to launch | Slow — requires designing and building full system infrastructure | Fast — API-based integration in days or weeks |
Initial complexity | High — OTP generation, routing, delivery, retries, fraud all built internally | Low — handled by provider |
Ongoing maintenance | Continuous engineering effort required | Minimal maintenance |
Control over system | Full control over routing, logic, and data | Limited to provider’s abstraction |
Global SMS delivery | Must manage carriers, routing logic, and regional constraints | Handled by provider |
Reliability engineering | Fully owned (failovers, redundancy, incident response) | Abstracted via provider SLAs and infrastructure |
Fraud & abuse prevention | Must be built and continuously updated | Built-in baseline protections |
Observability | Requires building dashboards and monitoring systems | Typically included out of the box |
Scalability | Requires continuous infrastructure investment | Scales automatically with usage |
Cost structure | High fixed + variable engineering + infrastructure costs | Usage-based pricing |
Vendor dependency | None, but replaced by internal ownership burden | Single-provider dependency |
Flexibility | Very high — fully customizable | Moderate — constrained by API capabilities |
Operational overhead | High — multiple systems and components to manage | Low — centralized via provider |
Questions to Ask Before Deciding
Instead of thinking of this as a binary “build vs buy” decision, it helps to evaluate your readiness across a few key dimensions.
Answering these questions can help clarify whether your team should build in-house or use a verification provider.
OTP Build vs Buy Readiness Quiz
For each question, choose the option that best reflects your current situation.
1. How critical is OTP to your core product experience?
A. It is central to user journeys and directly impacts conversion or revenue
B. It is important, but primarily functional (e.g. login, account access)
C. It is a supporting feature with minimal product differentiation impact
2. How would you describe your current infrastructure capability?
A. We already operate distributed, high-availability systems at scale
B. We have strong backend systems but limited experience with global delivery infrastructure
C. We do not currently manage infrastructure of this complexity
3. How important is full control over routing, delivery, and logic?
A. We need full control and customization across the stack
B. We need some flexibility but can accept abstractions
C. We prefer not to manage infrastructure-level decisions
4. How important is global delivery consistency across regions?
A. Critical — we operate globally and need optimized performance per region
B. Important, but occasional variation is acceptable
C. Not a primary concern for our use case
5. Do you have the capacity to own ongoing operational complexity?
A. Yes — we can support continuous monitoring, maintenance, and optimization
B. Partially — but we would prefer to minimize operational burden
C. No — we need a managed solution
6. How comfortable are you managing multiple vendors and systems?
A. We already manage multiple providers and are comfortable adding more
B. We prefer to minimize vendor complexity where possible
C. We want a single integrated solution
How to interpret your answers
Mostly A’s → You likely benefit from building in-house or deeply customizing infrastructure
Mostly B’s → You are in a hybrid zone, where APIs help but may not fully solve your needs
Mostly C’s → A verification API or managed solution is likely the best fit
No matter what your current situation is, one thing becomes clear over time: verification doesn’t stay simple for long, resulting in a fragmented system that must be actively managed and maintained.
From Fragmentation to Reliability: End-to-End Verification in One Platform
At this point, one thing is certain: OTP verification is not just a feature, it’s a system that requires coordination across multiple providers, routing logic, fraud protection and observability.
The real challenge, then, isn’t sending OTPs but operating the system behind them.
Solving the fragmentation problem
Most modern verification systems take a fundamentally different approach in that they no longer force teams to resort to assembling and managing multiple fragmented components.
Instead, they offer verification as a unified layer, where routing, redundancy, fraud protection, and observability are built into a single system.
The goal is not only to simplify implementation but also to eliminate the operational burden that comes with these systems.
End-to-End Verification, Built for Teams in One Platform
By the time teams reach scale, previously silent failures and hidden inefficiencies begin to surface.
Teams find themselves juggling multiple providers, managing routing logic, implementing fraud prevention, and building custom dashboards for monitoring.
What should be simple turns into a system that requires constant attention.
Prelude was built to remove that complexity entirely.
Prelude replaces this fragmented approach with a single system, one that handles routing, reliability, fraud protection, and observability.
Rather than assembling and managing all these components separately, teams can now rely on a system where everything works seamlessly together by design.
Multi-provider infrastructure, without the overhead
Prelude gives you access to multiple SMS providers globally by partnering with many providers to guarantee the highest possible delivery rate at the lowest possible cost, without needing to source, integrate or manage them individually yourself.
This means:
No vendor sourcing or procurement
No custom routing logic to build or maintain
Built-in redundancy across providers
What typically takes months to build is available right away out of the box.
Real-time routing and reliability
Prelude continuously monitors delivery performance for you and dynamically routes traffic to ensure high success rates.
Routing is handled automatically thanks to our routing engine which compares all available routes and selects the best one for each individual user.
If a provider underperforms or fails, traffic is automatically redirected without any impact on the user experience.
The golden metric: Beyond delivery rates
While tracking SMS delivery rates should be a priority, it’s not the only metric you should be focusing on.
Most OTP systems will focus on the initial step of the authentication process but overlook the next step, which is just as, if not more, important.
The real goal should be to measure conversion. In other words, how many users who received an OTP actually took the desired action as a result of this SMS?
Prelude's Verify API prioritizes time and conversion by dynamically routing users to the cheapest channel most likely to convert.
Built-in fraud protection
While many solutions offer anti-fraud features as an optional add-on, fraud detection is integrated directly into Prelude’s verification flow.
Our solution detects suspicious behavior in real-time by utilizing dozens of signals relating to each verification and draws on data from our vast database to predict whether a request is likely to be fraudulent.
The Prelude system continually learns from new fraud patterns in order to adapt to new attack vectors while granularly filtering the attacker from real users without resorting to blocking an entire country or network block.
No additional teams or integrations are required.
Unified visibility across your entire system
Prelude provides full visibility including real-time insights and alerting into your verification system, all in one place. This enables teams to track performance across regions, providers and delivery rates so they can track and quickly detect issues and optimize performance without having to build a custom dashboard themselves.
Cost optimization built into authentication
OTP costs quickly escalate due to high SMS pricing, fraud traffic, inefficient routing, and repeated retries caused by poor deliverability.
By combining intelligent routing, built-in fraud prevention, and optimized delivery paths, Prelude reduces unnecessary message volume and ensures each OTP is delivered as efficiently as possible. In cases where SMS is not the most effective channel, alternative delivery methods can be leveraged to further optimize cost and performance.
Instead of treating cost as a byproduct, Prelude makes it a controllable part of the system, delivering immediate and scalable cost savings.
From Complexity to Reliability
With Prelude, teams no longer have to juggle multiple providers, build and maintain routing systems, integrate fraud tools or create monitoring dashboards.
Instead, verification becomes infrastructure, one that is reliable, scalable and managed by design.
We do the heavy lifting so you can achieve:
Faster time to market by launching immediately without building infrastructure
Higher reliability with built-in redundancy and intelligent routing
Lower operational overhead since there’s no fragmented stack to manage
Better visibility with real-time insights across the system
Stronger protection with fraud prevention embedded by default
Conclusion
OTP verification doesn’t have to be a fragmented system.
The key is choosing the right approach, one that turns verification into infrastructure so teams can focus on building their core product, not maintaining the systems behind it.
The real question has to do with ownership and whether you want to build and operate your own system while managing the tradeoffs that come with it or rely on infrastructure that removes the burden altogether?
When it comes down to it, it’s not about how quickly you can implement verification but how effectively you can scale and operate it over time.
At the end of the day, sending OTPs is simple. Operating the system behind them is not.
Prelude was especially built to remove that burden by turning verification into reliable, scalable infrastructure so your team can focus on building their core product. Book a demo today and see it in action.
FAQs
What is an OTP verification system?
An OTP (One-Time Password) verification system is an authentication method used to verify a user’s identity by sending a temporary code via SMS, email, or app. OTP systems are widely used for login authentication, two-factor authentication (2FA), and account security in modern applications.
Why is building an OTP system complex?
Building an OTP system is complex because it requires more than sending a code. It involves distributed system architecture, SMS delivery infrastructure, retry and fallback logic, fraud detection, rate limiting, and global carrier integration. At scale, OTP systems must also handle latency, failures, and traffic spikes reliably.
When should you build an OTP system in-house?
You should consider building an OTP system in-house when you have strong infrastructure and security engineering capabilities, strict compliance requirements, or when authentication is a core part of your product. Teams operating at large scale may also benefit from building for greater control over performance and optimization.
What are the risks of building an OTP system internally?
The main risks of building an internal OTP system include high infrastructure complexity, ongoing maintenance overhead, security vulnerabilities, and fraud exposure. OTP systems require continuous monitoring and updates, and failures can directly impact user experience, login success rates, and trust.
What is SMS OTP fraud or SMS pumping?
SMS pumping is a type of fraud where attackers trigger large volumes of OTP messages to generate revenue or exploit messaging costs. This can lead to unexpected financial losses and increased infrastructure costs. SMS OTP systems are also vulnerable to bot-driven attacks and number recycling abuse.
How do OTP verification APIs work?
OTP verification APIs simplify authentication by providing pre-built infrastructure for sending and validating OTP codes. They typically include global SMS delivery, basic fraud detection, and retry handling. These APIs allow companies to implement OTP authentication quickly without building infrastructure from scratch.
What are the limitations of OTP verification APIs?
OTP verification APIs can introduce limitations such as dependency on a single provider, limited control over routing and delivery optimization, lack of deep observability, and generic fraud protection. At scale, these constraints can impact performance, cost efficiency, and reliability.
Why do OTP systems become fragmented at scale?
OTP systems often become fragmented as companies scale because they add multiple SMS providers for redundancy, build internal routing logic, integrate separate fraud detection tools, and create custom dashboards for monitoring. This leads to a complex, distributed verification stack that is harder to maintain.
What is the best approach to OTP authentication for scaling companies?
For scaling companies, the best approach depends on infrastructure maturity and product requirements. Many teams start with verification APIs for speed, but as they grow, they often need better control, observability, and multi-provider reliability. A unified verification infrastructure helps reduce complexity while maintaining global performance and security.
Start optimizing your auth flow
Send verification text-messages anywhere in the world with the best price, the best deliverability and no spam.

